In Part 1, we discussed how using joint embeddings to rank images can help address the cold start problem. We showed that the joint embedding ranker exposes more new images than our existing ranker. This difference was even more pronounced for popular queries, where our existing ranker tends to favor older images that have more behavioral data.
In this part, we will explore some of the additional benefits we found of the joint embedding ranker.
Additional benefits
In addition to improving the cold start problem, we found that using joint embeddings addresses a number of problems inherent to our ranking approach. In this part we will explore some of those findings.
1. Multilingual search
Shutterstock supports search in over 20 languages. Supporting search in multiple languages requires expertise in a number of technical domains:
- Language detection: While a user can set the display language of the site, the setting alone will not predict what language the user will search in.
- Translation: A working translation system for search requires the capability to translate both words and phrases. A proper translation system requires language-specific information retrieval knowledge—segmentation, stemming, and character normalization all have different rules in each language.
- Search: Along with the aspects above, the search system has to handle multilingual search problems, such as terms that have multiple translations in the target language and queries that include words from multiple languages.
In addition to the challenge of requiring many different technical skills, the dependencies in such as system make enhancements difficult. An improvement to language detection might negatively affect the accuracy of the translation, a change to the translation system could require a corresponding change to the search configuration, etc.
Preliminary experiments show that we can train a jointly-embedded multilingual model that addresses many of these issues. We will discuss the details of our multilingual model in a future post, but one of the key takeaways is that we were able to get competitive results without utilizing the techniques mentioned above. Building a multilingual search system without requiring such breadth of expertise is very compelling.
2. Stemming
Text-based search engines often rely on exact word matches to retrieve results. To increase recall (i.e. retrieve more relevant images), many search engines reduce all words in the index and queries to their stem. For example, “running”, “runs”, “run”, and “runner” will all be reduced to “run.” While this method is highly effective, it may lead to erroneous results. Our joint embedding ranker does not use word matching to retrieve results so it does not suffer from this issue. Below are a couple example failures in our popular ranker that are handled properly in the joint embedding ranker:
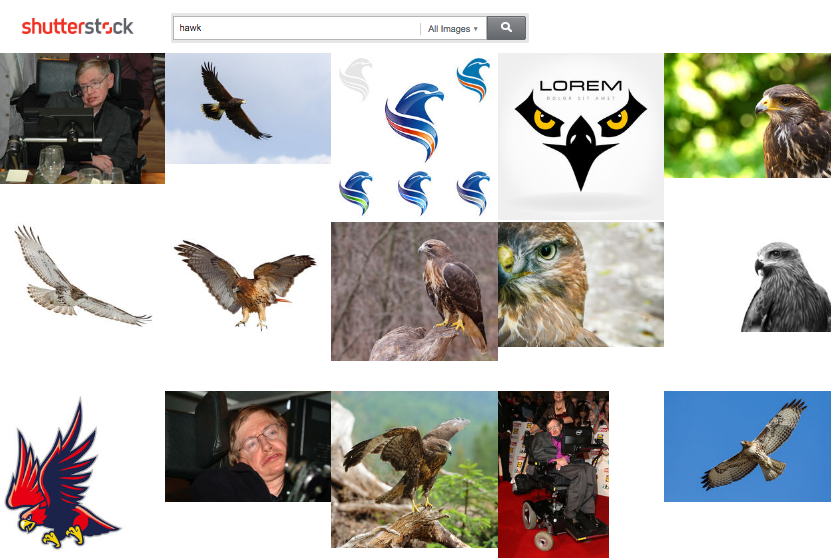
Traditional ranker results for “hawk”
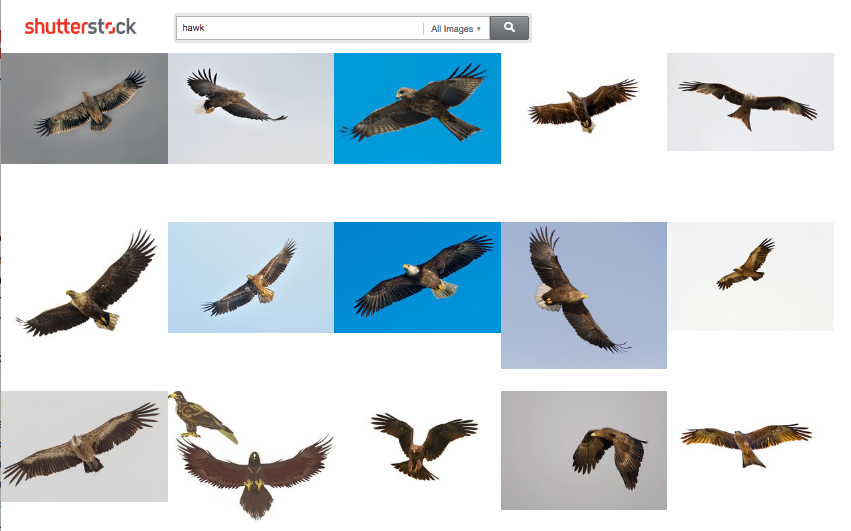
Joint embedding result for “hawk”
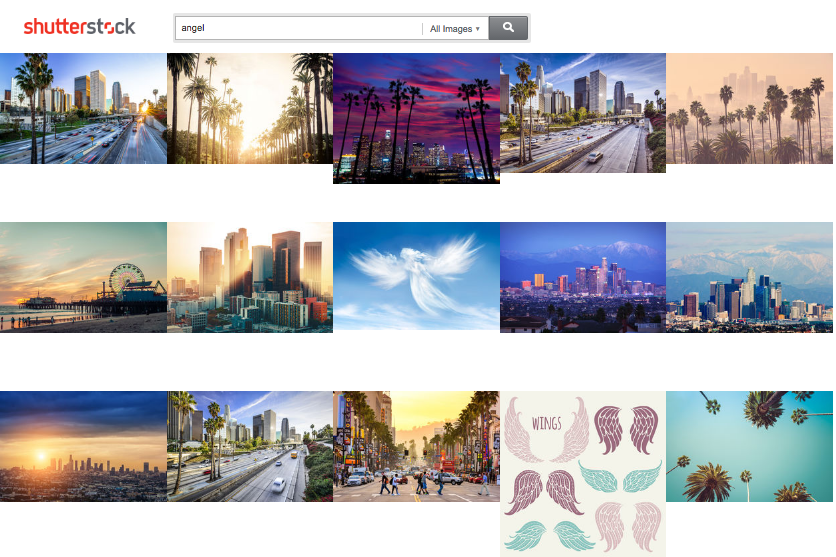
Traditional ranker results for “angel”
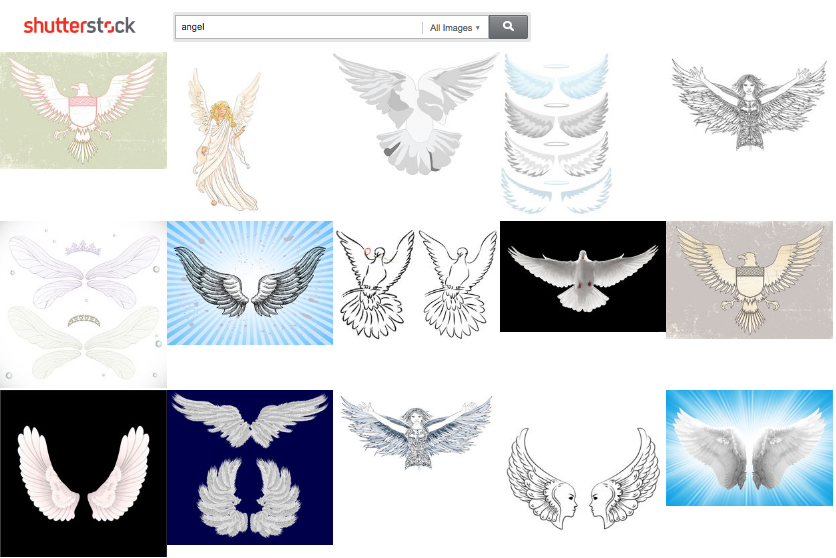
Joint embedding results for “angel”
As can be seen from these examples, there are words that have multiple meanings, where each meaning is restricted to a set of the word forms. In these situations, stemming causes a confusion between the meanings—“Hawking” is returned for “hawk” and “Angeles” is returned for “angel.” Similar examples can be found where neither word is a proper noun (e.g. “goatee” and “goat” have the same stem). There are various mechanisms for handling stemming errors, but they typically involve a manually curated list of terms that are exempt from stemming. Our approach removes the need for this manual labor.
3. Word misattribution
Another issue with traditional ranking approaches is word misattribution. When evaluated for ranking purposes, a query in our behavioral data is tokenized into individual words. This can lead to poor results when we encounter non-compositionality: words in a phrase that have a different dominant meaning when considered independently. For example, the most common meaning of the word “bowl” is different than its meaning in “Super Bowl.” In the context of search, more subtle differences in meaning can lead to poor results. Our data shows that, when users search for “happy”, they are likely to be looking for images representing the emotion directly, rather than images representing specific special day celebrations such as “Happy new year” or “Happy birthday,” The joint embedding language approach considers the entire query when building its language model, rather than assuming composition, so it tends to handle contextual meaning much better than our traditional ranker. This can be seen in the results below:
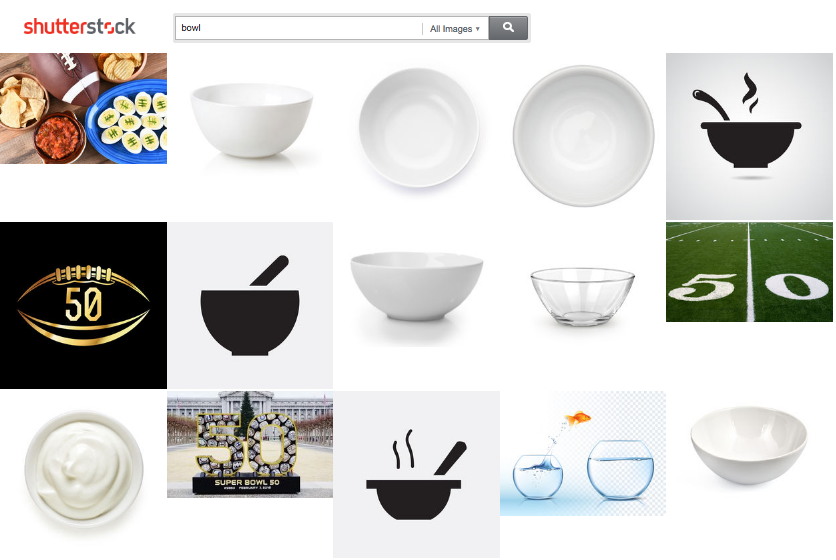
Current ranker result for “bowl”
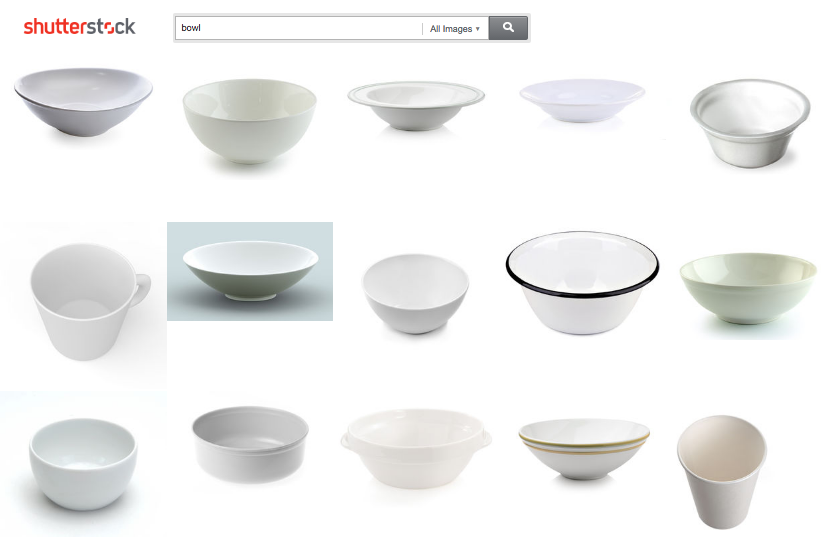
Joint embedding result for “bowl”
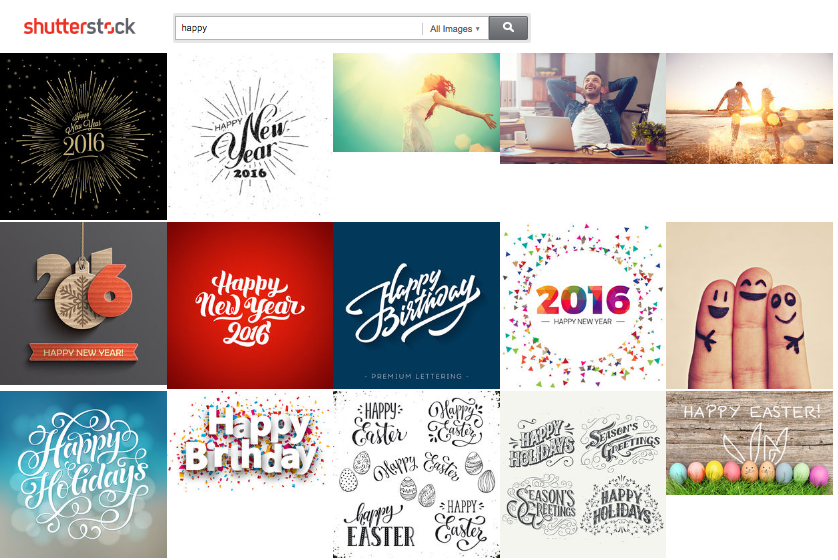
Current ranker results for “happy”
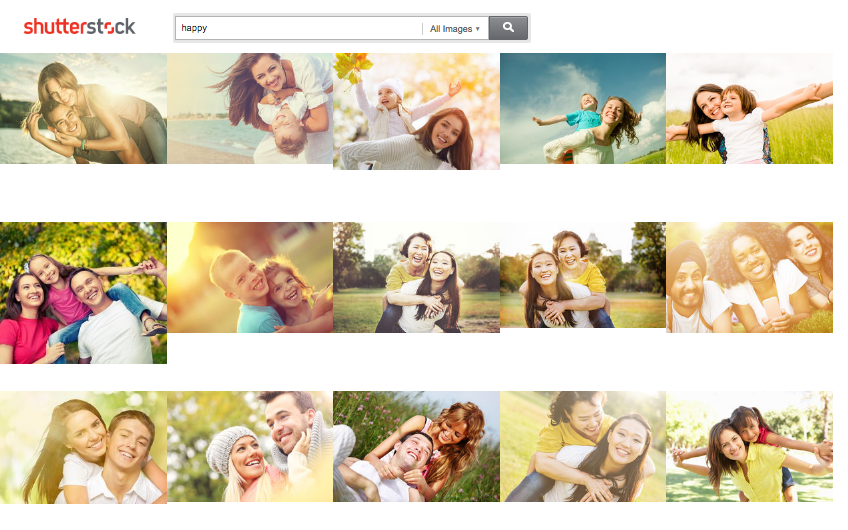
Joint embedding result for “happy”
Although all three of the above-mentioned benefits are addressable within the current ranker, they require effort and additional complexity, where our proposed approach addresses these issues directly.
Conclusion and future work
The results of our joint embedding ranker are promising. They surface many more new images and can provide more relevant results. Still, joint embeddings still have a few deficits as a ranker. The most notable deficit is the lack of diversity in the results. At query time, the model determines the appropriate point for the query in the vector space. We then sort the images in the collection by proximity to that point. Unfortunately, this often leads to all results for a query being visually similar. The lack of diversity exposes important nuances of the text-to-image search problems: It’s difficult to describe an image in words, and queries have multiple meanings. There are several possible solutions to this issue which we will explore in future work.
We’ve shown that joint embeddings can help us address the cold start issue in rankings, as well as a number of issues with our text-based approach. We believe this is just the beginning. Future uses of joint embedding could enable a number of new features and feature enhancements. Translation, automatic query expansion, advanced pixel search, ranker failure detection, and image style personalization can all be improved with this technique.


